In this blog post I’d like to tell one story that had happened with one Haskell application. Then I’ll explain how can we start threaded RTS in a way so it is aware of the CPU layout of your system. If you want to skip the story you may proceed to the solution directly.
Some updates to this post can be found in the next one.
Recently I’ve written a small Haskell application that performs some cryptography routines, query management, and communication with Redis. We wanted to test the capabilities of the application and measure RPS that application can support. We used Yandex Tank for this purpose. Yandex tank can generate a load for a site and build some fantastic reports (it could require GitHub authorization).
Results were quite interesting. At first everything went well: the application was able to process about 1k requests per second and that was enough for the expected load. However, when Yandex Tank gave a pressure of about 2k RPS the situation became worse. The application stopped being responsive. It was able to process only 200 requests per second. That was troublesome. On the Yandex tank plots there was a period of reasonable performance and then a period of unresponsiveness.

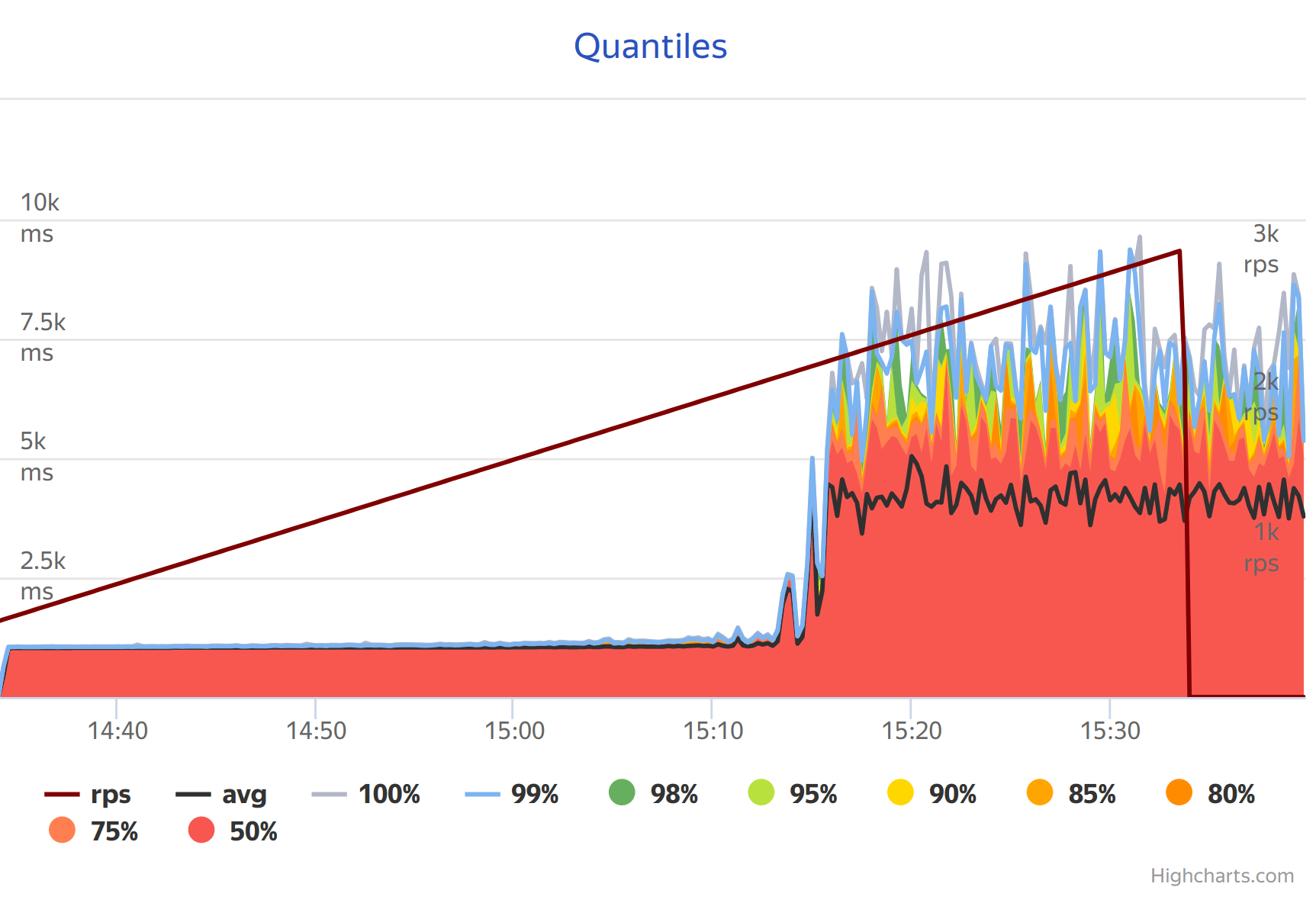
As it happens the first suspect in such cases is the Garbage Collector. You can always hear lots of scary stories about how GC could ruin your life. Keeping that in mind GC was tuned beforehand and I had prepared some metrics. However this time the situation was quite OK: garbage collector pauses were all below 10ms and 99% of the total program time was spent on actual work and not on garbage collection. Memory usage was too big - around 700Mb and I didn’t expect that.
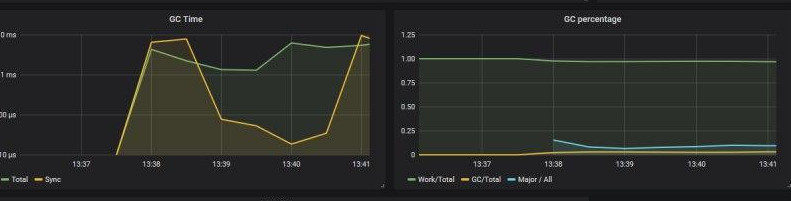
On the left plot you can see reports of the last GC, they are not very precise as they may miss some GCs or report the same GC twice. However they still tell us the order of magnutude. On the right plot we see the ratio of the time spent in mutator to the total running time.
Other parts of the system were not under a stress and were capable of handling higher loads. So the issue was in my program. Although I didn’t spend much time optimising the program, it should behave better.
Another surprising fact was that the issue didn’t appear on my system which is comparable to the one where stress tests were running, and the one that could handle higher load. Accidentally I realised the difference, and the following dialogue took place:
Me: What is the CPU on the system?
Admin: I7 4 cores, eight thread!
Me: Ah! Add
GHCRTS=-N4to the container’s Environment.
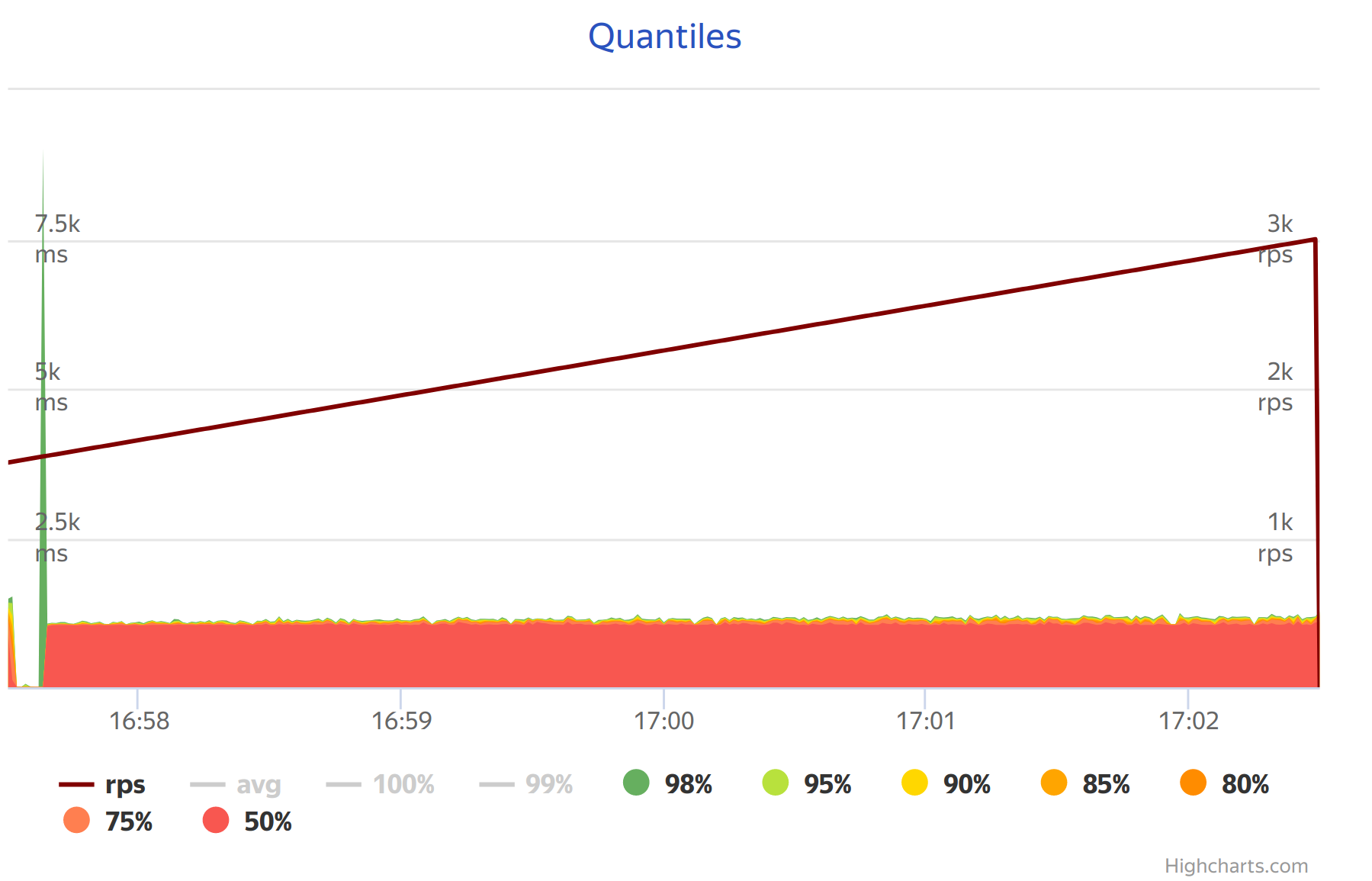
After that single adjustment the situation changed drastically: the program was now able to process 4.5k RPS (comparable to the maximum load that a single instance of Yandex.Tank can generate), now mutator time got >99%, GC pauses were still ~10ms but very rare and memory usage was about 25Mb.
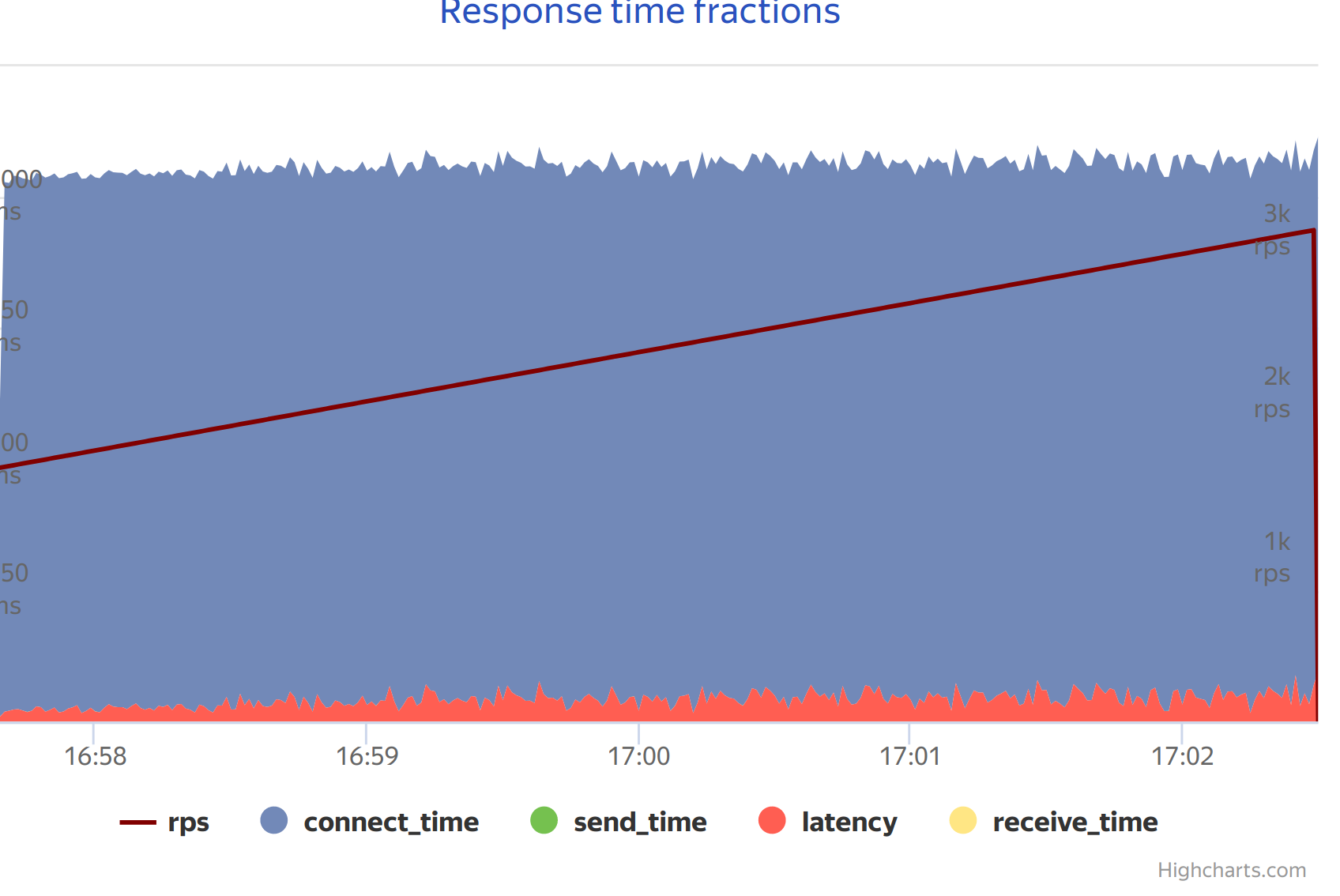
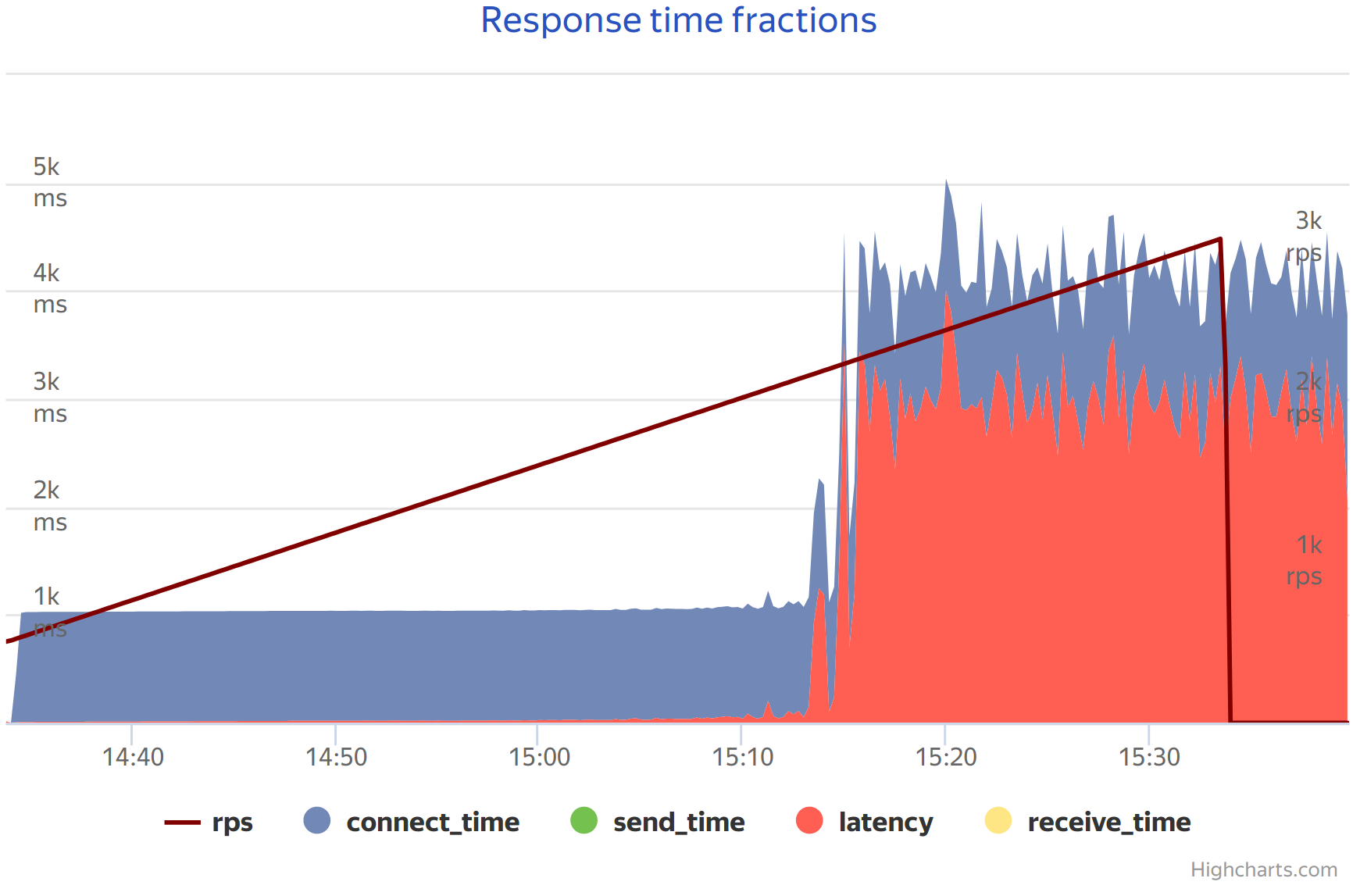
Connect time was still terrible in that case but it was fixed by reconfiguring and improving network which is out of scope here.
So this is just another story about suboptimal defaults for the runtime system. It happens that if you pass +RTS -N option - you tell runtime system to start the same number of capabilities as the number of cores you have. However, RTS makes no difference between real and virtual cores. It appears that RTS could not make enough benefit from virtual cores and performance is not good enough in that case.
While it is pretty impressive that we can optimise a program without any changes in source code, it’s interesting what can we do in general case. It’s problematic that we can not set good options which work on any CPU and have a decent performance. To find an answer I’ve started the project ht-no-more. It lives in my playground for now but I can extract it to a separate repo. I hope that at some point it will be mature enough to be used as a library or even land to into the RTS source code.
Solution
The idea is to gather information about the architecture during a program startup and then set up an RTS with a proper configuration. We want:
- collect information about a CPU (how many real and how many virtual cores do we have);
- do not allow RTS to run work on virtual cores;
- make it so
+RTS -Noption still behaves well.
N.B. From this place and now on we assume that we run on Linux only and that we have procfs mounted and that we can write non-portable code. Now our life is comfortable, and we can proceed with the task.
The first question is how can we tie our process to a CPU. There are sched_getaffinity() and sched_setaffinity() calls. Those methods perform hard wiring of a process and all it’s descendent processes to given CPUs. So we can use them to mask CPUs that we are not interested in.
int sched_setaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *mask);
int sched_getaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *mask);First let’s write a simple c program that explains the API.
#define _GNU_SOURCE // allow to use non-portable functions
#include <sched.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char * argv[]) {
cpu_set_t set; // define CPU set
CPU_ZERO(&set); // mark all CPUs as unused
CPU_SET(0, &set); // allow to use first CPU
sched_setaffinity(0, sizeof(cpu_set_t), &set); // wire process to CPU
int result = system("bash"); // start bash.
return result;
}In this first program we allow an application to run only on the first CPU. We need this program later for testing purposes. I’ve used it to check if my program behaves well in the constrained case.
The next question is how to check if a processor is real or virtual. The only way I’ve found it is to parse /proc/cpuinfo file. We are interested in core id entry for each processor: it tells what the index of the real core that CPU is set on is. For example on my machine I have:
As I have Hyper-Threading disabled - all cores are real ones. On digital ocean host, I have:
all CPU are on the same core (at least for the container).
Now we can combine the answers to the questions and write the code. We need to remember that there is an additional case that we want to cover: if the CPU was already disabled for our program – then we don’t want to “unmask” it. As a result, I ended up with the following code:
int setcpus() {
cpu_set_t set;
int ret = 0;
ret = sched_getaffinity(0, sizeof(cpu_set_t), &set);
if (ret == -1) {
fprintf(stderr, "Error: failed to get cpu affinity");
return 0; // We instruct code that we have failed and it should fallback to the normal procedure.
}
int current_cpu = -1;
int current_core = -1;
FILE *cpuinfo = fopen("/proc/cpuinfo", "rb");
char *arg = 0;
size_t size = 0;
while(getdelim(&arg, &size, '\n', cpuinfo) != -1)
{
if (strstr(arg, "core id") != NULL) {
current_core++;
char * found = strchr(arg, ':');
if (found) {
int cpu = atoi(found+1);
if (current_cpu != cpu) {
current_cpu++;
if (CPU_ISSET(current_core, &set)) {
CPU_SET(current_core, &set); // XXX: this is noop.
fprintf(stderr, "%i real core - enabling\n", current_core);
} else {
fprintf(stderr, "%i was disabled - skipping\n", current_core);
}
} else {
fprintf(stderr, "%i is virual - skipping\n", current_core);
CPU_CLR(current_core, &set);
}
} else {
return 1;
}
}
}
ret = sched_setaffinity(0, sizeof(cpu_set_t), &set);
if (ret == -1) {
fprintf(stderr, "Error: failed to set affinities - falling back to default procedure\n");
procno = 0;
} else {
procno = current_cpu;
}
free(arg);
fclose(cpuinfo);
return 0;
}Now we are ready to build a cabal project. I’m skipping all irrelevant things that are generated by cabal init
executable ht-no-more
main-is: wrapper.c
other-modules: Entry
build-depends: base >=4.10 && <4.11
default-language: Haskell2010
ghc-options: -no-hs-mainTo highlight the important things: first of all, our main module is a C file. It does not work with old cabal’s that allowed only Haskell modules to be the main one. Then we add -no-hs-main – an option that tells GHC not to create its own “main” and use the “main” function that we define. We define Entry.hs Haskell module that provides an entry function because we no longer have one. In that module we create a single function that tells how many capabilities RTS have created.
module Entry where
import Control.Concurrent
foreign export ccall entry :: IO ()
entry :: IO ()
entry = print =<< getNumCapabilitiesThe only non-trivial thing we need is to export a foreign function. Compiler generates a C complatible object called entry that we can call from C.
We follow GHC User’s Guide to define our main function (sidenote, if you haven’t read GHC User’s Guide, please do, it’s the most authoritative and precise source of information about GHC features and extensions).
#include "HsFFI.h"
#ifdef __GLASGOW_HASKELL__
#include "Entry_stub.h"
#include "Rts.h"
#endif
int main(int argc, char * argv[]) {
setcpus();
#if __GLASGOW_HASKELL__ >= 703
{
RtsConfig conf = defaultRtsConfig;
conf.rts_opts_enabled = RtsOptsAll;
hs_init_ghc(&argc, &argv, conf);
}
#else
hs_init(&argc, &argv);
#endif
hs_init(&argc, &argv);
entry();
hs_exit();
return 0;
}However, we have not done everything. If you try to compile this program and run it with RTS +N you’ll see expected logs but the program reports that you are using the number of capabilities equal to the number of virtual cores. It happens because with RTS +N GHC asks the number of configured processors and creates that number of capabilities. Instead of this we want the count of capabilities to be equal to the number of real cores. Furthermore, we don’t want to patch GHC just yet because our code is too hacky.
GHC RTS is linked statically with each Haskell project. It means that we can use a linker to make RTS use our method instead of the one provided with GHC, we are interested in redefining uint32_t getNumberOfProcessors(void). For that reason we use linker’s wrap feature. If you tell linker -Wl,-wrap, function then for each call to the function it calls __wrap_function instead and generates __real_function that you can call to call the original function.
So we write
static uint32_t procno = 0;
uint32_t __real_getNumberOfProcessors(void);
uint32_t __wrap_getNumberOfProcessors(void)
{
if (procno==0) {
return __real_getNumberOfProcessors();
} else {
return procno;
}
}to get the desired result. We change cabal to provide required options to the build:
ghc-options: -no-hs-main
-threaded
-optl-Wl,-wrap,getNumberOfProcessorsYou can find the full code on GitHub. There is still much work for this project before you can use it for your application.
There is some further work which could be done:
- The code could be cleaned and prettified;
- The code could be made portable and be able to run on all OSes GHC can run on;
- The current approach may be not sub-optimal, maybe it’s enough to redefine
getNumberOfProcessorsalone without callingsched_setaffinity. - I didn’t test the interference with other functions; for example, if you run a program with
-xmflag (that pins capability to CPU) it may fail. - It’s possible to extend this solution and set better GC options based on CPU info
- I’m curious if it is possible to write this program as a library and reuse in other projects.
All feedback is welcome.
comments powered by Disqus